爬虫规则不清楚
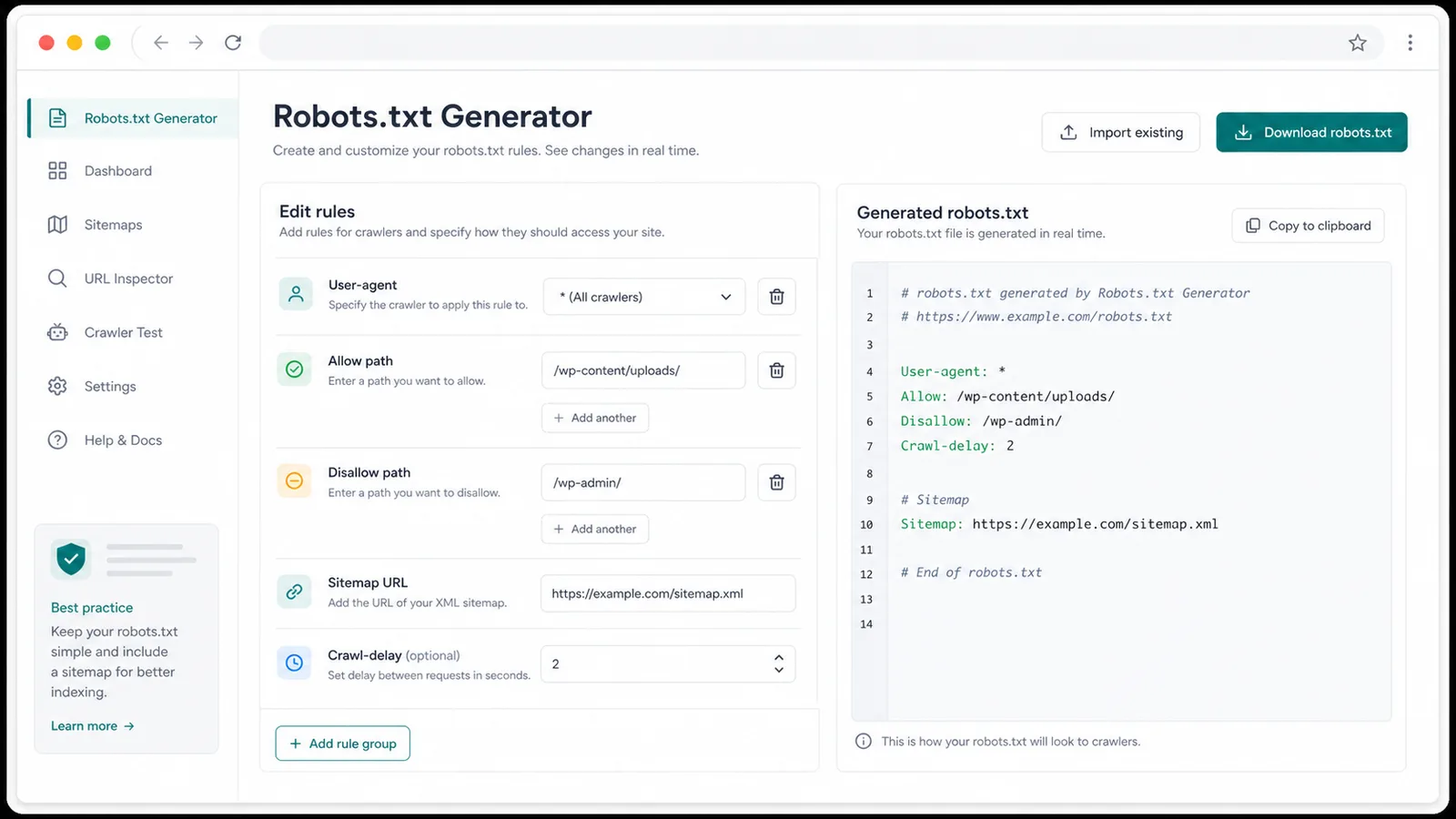
Robots.txt 生成器把零散的允许和禁止路径整理成清晰的 User-agent 规则组。
免费 SEO 工具
Robots.txt 生成器适合独立站站长、新网站上线和 SEO 基础配置。选择爬虫模板,填写路径规则和站点地图,一键复制或下载 robots.txt。
robots.txt 的小错误可能阻止上线页面抓取、暴露测试路径,或让站点地图入口不清晰。
Robots.txt 生成器把零散的允许和禁止路径整理成清晰的 User-agent 规则组。
添加一个或多个完整 Sitemap 地址,帮助爬虫找到已发布的 XML 站点地图。
从所有爬虫、Googlebot 或 Bingbot 模板开始,只调整真正需要的路径。
把 Robots.txt 生成器作为上线前的爬虫访问配置清单。
为 *、Googlebot、Bingbot 或自定义爬虫创建独立规则组。
添加多条路径,保持目录规则清晰,并提示未以 / 开头的路径。
在生成的 robots.txt 末尾输出一个或多个 Sitemap 行。
在支持时填写 Crawl-delay,并在 Googlebot 规则中提醒该字段不适用。
复制生成内容,或直接下载 robots.txt 文件用于部署。
Robots.txt 生成器在浏览器中运行,不上传站点路径。
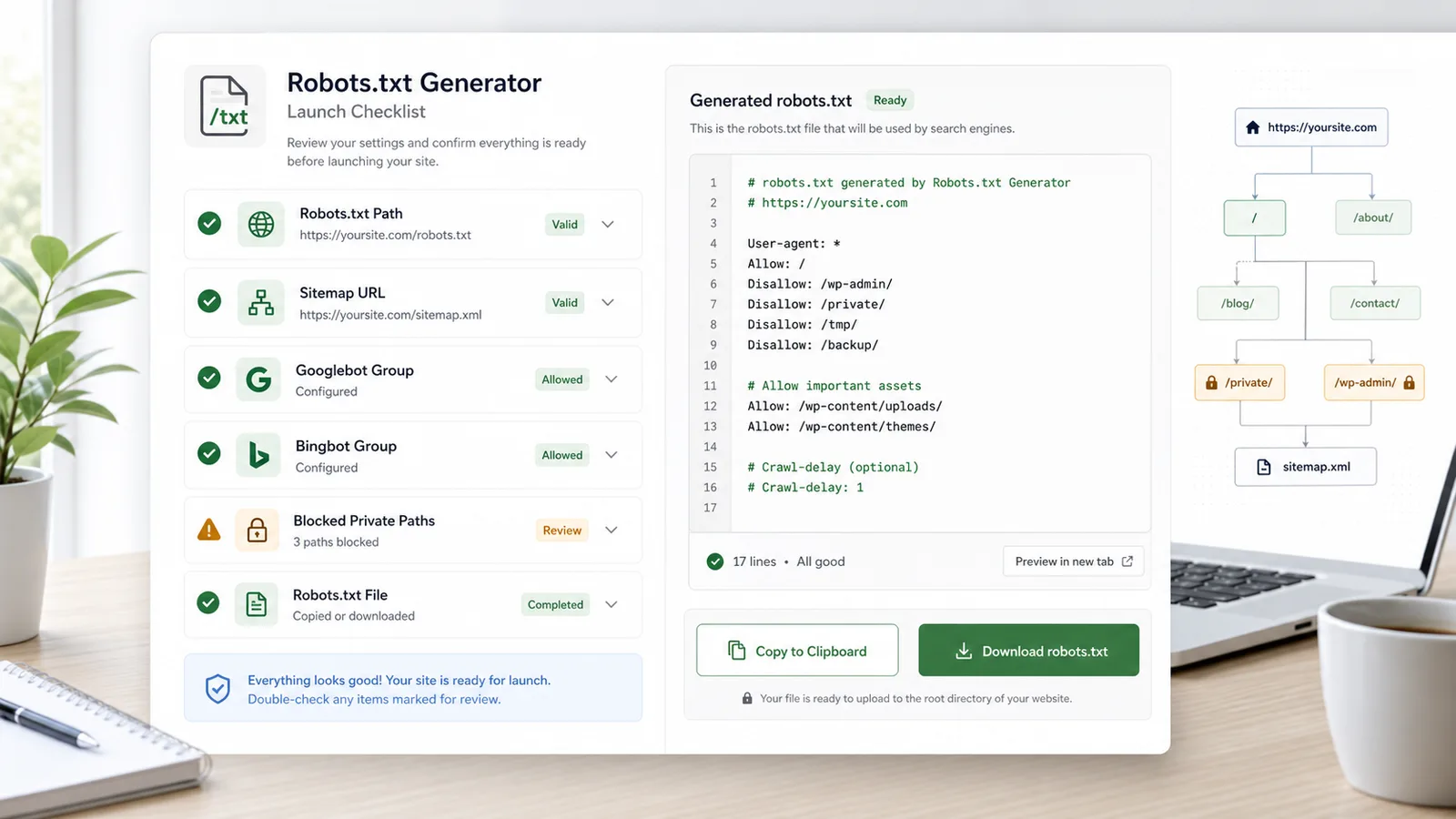
先生成草稿,再复核规则,最后上传到对应站点根目录。
新网站上线、保护私有路径、标准化 SEO 基础配置时,都可以使用 Robots.txt 生成器。
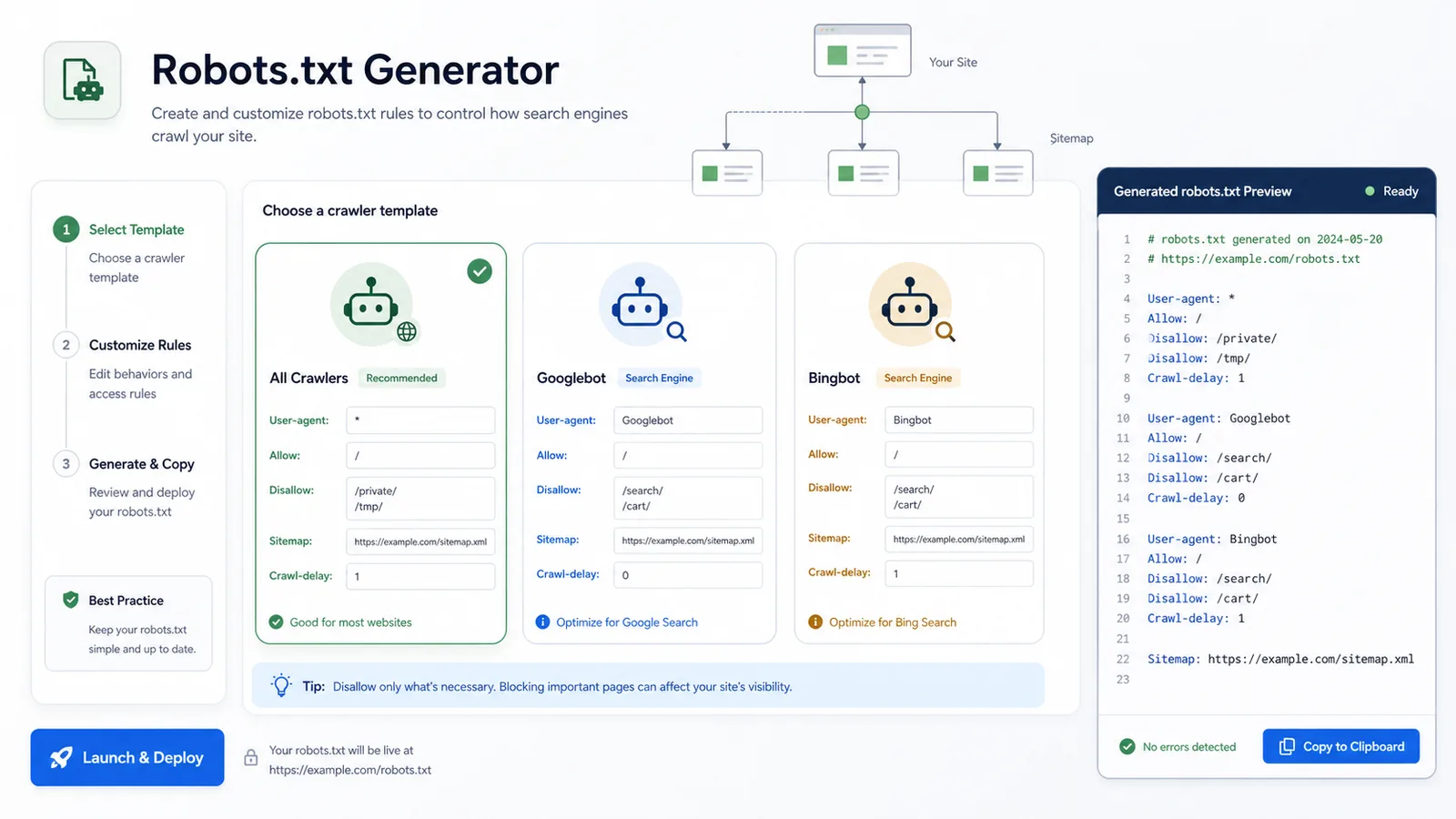
Robots.txt 生成器适合日常 SEO、开发和内容发布流程。
不用手写每一条指令,也能为新网站创建简单 robots.txt。
确认重要页面允许抓取,私有路径、重复路径或结账路径按需禁止。
生成可提交、可复核、可上传到站点根目录的文件。
发布新栏目之前,统一站点地图和爬虫访问规则。
robots.txt 控制抓取,不等于保证索引处理,因此仍需上线后复核。
如果站点是 https://example.com/,文件应可通过 https://example.com/robots.txt 访问。
Sitemap 行应使用完整 URL,避免爬虫推断 www、非 www、http 或 https 版本。
使用 Robots.txt 生成器后,在无痕窗口打开最终地址,并在搜索引擎工具中验证。
关于 robots.txt 规则、Crawl-delay 和 Sitemap 的常见问题。
不能。robots.txt 控制抓取。如果搜索引擎从其他地方发现 URL,被阻止抓取的 URL 仍可能显示;需要控制索引时应结合 noindex 或移除工具。
不支持。Google 文档列出 User-agent、Allow、Disallow 和 Sitemap,并说明 Crawl-delay 这类不支持字段会被忽略。
上传到对应主机根目录,例如 https://example.com/robots.txt。
可以。Robots.txt 生成器支持每行一个 Sitemap 地址,并输出多条 Sitemap 指令。